
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 과제 잘하기
- TIZEN
- 비에이 맛집
- 노보리베쓰 맛집
- adsense
- java oracle
- 카르마 부품
- 서울에서 1시간 캠핑장
- 카르마 개봉
- 훗카이도 렌트카
- 비에이 렌트
- MIT Technology review
- 오타루 맛집
- 노보레베츠
- 훗카이도 맛집
- MIT
- 신치토세 공항 렌트카
- 카르마 스태빌라이저
- 삿포로 렌트카
- 블루리본
- 과제 잘하는 방법
- 후라노 맛집
- 북해도 맛집
- 삿포로시 맛집
- 북해도 양갈비
- 닭도리탕
- 경주
- 드론 카메라
- 카르마 그립
- 북해도 양고기
- Today
- Total
필피리의 잡학사전
2018 자연어 처리 튜토리얼 본문
한국정보과학회 언어공학연구회에서 주관하는 2018 자연어처리 튜토리얼을 참가한 뒤 정리하는 글입니다.
아래 이미지는 전체적인 일정 및 등록비 정보입니다.

<출처: www.hctl.kr>
지난 2월 20일에서 21일까지 이틀간 총 8명의 교수님들이 자연어처리에 대해 각기다른 주제로 강의를 했습니다.
지금 작성되는 포스팅은 각 강의에 대한 요약이라기 보다는 강의를 듣고 자연어 처리의 전체적인 큰 그림을 그려보는 시간입니다.
포스팅의 순서는 강의 순서와 무관하며, 저의 개인적인 정리가 많이 포함될 수 있습니다.
또한 제 자신이 nlp 분야에 처음 발을 내놓는 것임에 잘못된 내용이 포함될 수도 있으니,
그런 것들은 언제든지 말씀해주시면 수정하겠습니다.
이번 게시글의 목적은 개인 정리 용도가 가장 큽니다.
자연어를 처리하면 다양한 분야에서 응용할 수 있습니다.

<임희석 교수님 강의자료>
먼저 컴퓨터의 언어처리 단계는 우리의 뇌와 달리 step을 여러개로 나누어 처리합니다.
아래 그림을 보시면 알겠지만 다양한 처리 및 분석 단계가 있습니다.
우리의 뇌는 언어를 들을 때 컴퓨터가 지금 하는 것처럼 귀로 들어온 언어들을 분리하거나 그것을 다시 분석한 다음 분석된 결과들을 다시 합치는 작업을 하지 않습니다.
하지만 컴퓨터가 자연어처리를 위해 이렇게 분리하고 분석하는 이유는 언어가 복잡하기 때문입니다.
언어는 표현된 문장이 글자 그대로 이해가 되는 경우도 있지만,
단어의 모호성이나 동의어 등에 따라 의미가 달라지기도 하고 앞 문장과 뒷 문장의 연결성에 의해 분석하는 것이 더욱 어렵습니다.
이러한 이유들로 컴퓨터가 언어를 처리할 때에는 단계를 여러개로 나누어 문장과 단어들을 분석을합니다.
컴퓨터가 전통적으로 한국어를 처리하는 과정은 아래 그림으로 표현할 수 있습니다.
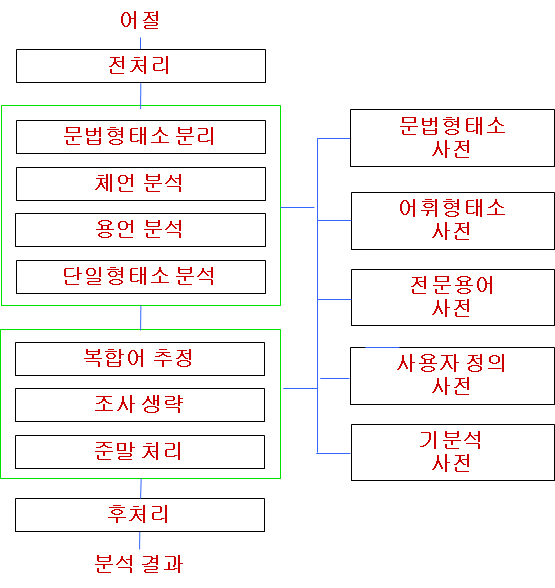
<강승식 교수님 강의 자료 中>
어절이 입력되면 전처리라는 과정을 거칩니다.
전처리는 쉽게 말해 쉼표나 마침표 등 언어처리에서 필요없는 부분들을 제거하는 과정입니다.
어절자체로는 컴퓨터가 의미 파악하기 어려우니 한국어 처리에서는 형태소를 분석하는 작업이 추가됩니다. 여기서 형태소란 뜻을 가진 가장 작은 말의 단위를 말하며, 형태소를 나누면 뜻이 파괴됩니다. 분석된 결과는 품사 부착을 통해 품사 태그를 갖게 됩니다.
한국어에서는 형태소들을 품사 태그 테이블에 맞게 분류하며 아래 링크에 여러 개의 품사 태그에 관련된 내용들이 테이블로 정리되어 있습니다. 품사 태그 테이블은 하나가 아니라 분석기를 개발하는 분들이 각자 진행하는 프로젝트에 맞는 것을 찾아서 사용하거나 직접 만들어 사용합니다.
아래 링크에는 한국어 형태소 분석기 및 구문 분석기의 모음이 정리되어 있습니다.
https://github.com/nearbydelta/KoalaNLP
다양한 형태소 분석기들을 쉽게 사용할 수 있도록 하나의 인터페이스로 만들었다고 합니다.
저도 아직 사용해보지 않아서, 사용해보는대로 포스팅을 작성하여 업데이트 하도록 하겠습니다. 자연어를 처리하는 개발자들이 매번 형태소 분석기 등을 만드는 것이 아니라 기존에 제공되는 것들을 갖다 사용한다고 보면 되겠습니다.
오픈소스 형태소 분석기를 사용하여 품사태그를 달아보는 방법 포스팅!
형태소 분석 후에는 문장 구성요소들 간의 관계를 분석하는 구문 분석 작업을 합니다.
형태소들 사이에 위계 관계를 분석하여 문장의 구조를 결정합니다.
구문 분석 후 의미 분석 과정도 필요합니다. 한국어에는 다의어가 존재하기 때문에 분석 대상이 어떤 것을 의미하는지 파악하는 것도 필요합니다.
이렇게 전통적으로 문장을 분석하는 접근법은 크게 2가지로 설명될 수 있습니다.
1. 규칙기반
규칙을 만들어서 문장을 분석합니다. 이 경우 문장을 분석하기 위한 모든 규칙을 다 만들어야 합니다. 하지만, 문제로 제기되는 경우로 규칙을 추가하다보면 기존에 추가되었던 규칙들과 충돌이 나는 문제를 볼 수 있습니다. 예전부터 사용해오던 방식이고 이번 튜토리얼에서는 부산대학교 권혁철 교수님이 관련해서 강의를 해주셨습니다. 최근 딥러닝을 이용한 연구들이 많지만, 권혁철 교수님은 룰베이스 기반이로도 충분히 높은 성과를 낼 수 있다는 것을 보여주기 위해 계속 연구중이라고 합니다.
2. 통계적 접근
통계적인 접근을 통해 문장을 분석합니다. 통계를 위해서는 tag된(품사태깅) 말뭉치들이 필요한데, 정확한 결과를 위해 엄청나게 많은 데이터가 필요합니다. 울산대학교 옥철영교수님은 이번 튜토리얼에서 한국어 의미분석에 대한 강의를 해주셨습니다. 동의어나 단어 연산에 대한 연구를 주로 하셨는데, 이를 위해 모든 단어를 의미에 따라 분류하고 트리를 만들어서 사용했습니다. 아래는 울산대학교 옥철영 교수님 연구 관련 링크입니다.
최근에는 딥러닝이 대세인 만큼 문장분석을 CNN, RNN, RL 기법등을 이용한 문장 분석방법이 활발하게 연구되고 있고,
사용되고 있습니다. 이번 튜토리얼 강의에서도 대부분이 딥러닝에 대한 주제가 많았습니다.
저 또한 전통적인 방법 보다는 딥러닝을 이용한 분석방법에 더 관심이 많기 때문에 그부분에 초점을 맞춰 정리를 하고,
앞으로의 포스팅 방향성도 딥러닝의 알고리즘들이 주제가 될 것입니다.
NLP에서 최근 트렌드는 Distributed Representation, CNN, RNN, Deep Reinforced Model and Deep Unsupervised Learning, Memory Augmented가 있습니다.
이렇게 용어들만 쭉 나열하면 저도 잘 모르겠습니다. 조금은 풀어보도록 하겠습니다.
Distributed Representation
문장이나 단어는 인간이 이해하는 단어입니다. 이것들을 직접 컴퓨터에게 전달하면, 컴퓨터는 인간의 문장들을 이해할 수 없을것입니다. 그래서 오래전부터 단어를 숫자 혹은 벡터로 변환해왔고, 어떻게하면 더 효율적일 수 있을지에 대해 연구해왔습니다.
많이들 알고계시는 one-hot encoding이 컴퓨터가 인지하는 방법 중 하나의 예입니다.
(ex, smart phone = [0,1,0,0], smart watch = [1,0,0,0]
하지만 이 방법은 단어마다 사람이 직접 구축을 해야하며 단어와 단어사이의 관계를 명확히 알기 어렵습니다.
1980년대부터 이러한 문제를 해결하고자 연구들이 시작되었고,
2000년대 들어 RNNLM, skip-gram등으로 발전,
2013년에는 google 형님들께서 word2vec을 발표하며 널리 세상을 이롭게 하였습니다.
Word2vec은 2층으로 이루어진 신경망으로 문서의 큰 말뭉치들을 입력으로 받아 벡터 공간에 단어를 표현합니다.
보통 수백개의 차원으로 이루어진 벡터에 표현되는 단어를 통해 단어들간에 관계를 이용하여 다양하게 활요할 수 있습니다.
CNN (Convolutional Neural Networks)
주로 CNN은 computer vision분야에서 많이 사용됩니다.
Convolution은 합성곱으로 아래에 간단한 gif된 예제가 있습니다. (3*3 행렬이 기존 image 행렬을 sliding하며 계산된 값을 저장합니다)
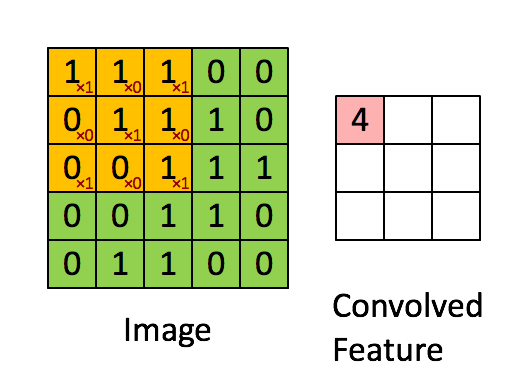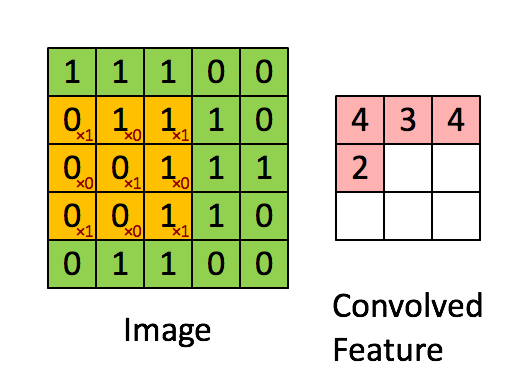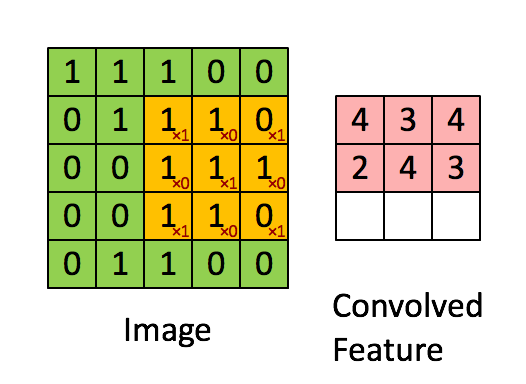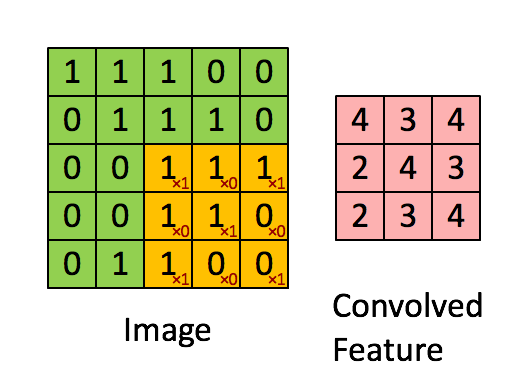
<http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution>
CNN은 여러 층의 convolution으로 구성되어진 것입니다. 전통적인 neural network은 각 입력 뉴런을 출력 뉴런으로 연결합니다. 하지만 CNN은 출력을 계산하기 위해 입력 단계에서 convolution을 사용하고, 지역적인 convolution으로 연결됩니다.(아래 그림 참조)

<http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/>
각 층은 수백에서 수천개의 다른 필터들을 적용하고 그들의 결과를 결합합니다. 중간 중간 pooling 이라는 작업도 하는데 이 것은 다른 포스팅에서 더 자세히 설명하도록 하겠습니다.
CNN을 이용하여 교육 단계에서 자동적으로 원하는 결과가 나오도록 filter가 가치를배우게 됩니다.
그렇다면 CNN을 nlp에서는 어떻게 적용할까요?
입력을 image pixel대신 matrix로서 표현된 문서 혹은 문장으로 합니다. 앞에서 얘기했던 one-hot encoding, 혹은Distributed Representation 등을 이용하여 문장을 matrix로 변환합니다.
어떤 방식이던 단어를 matrix로 변환했다면, 그것이 우리의 image가 되는 것입니다.
사실 image는 지역적인 요소들이 어디에 위치했다고 해서 결과에 큰 영향을 미치지 않지만, 언어는 다릅니다. 구성요소들 사이에 물리적인 거리에 따라서 의미가 달라질 수있고, 거리가 멀다고 해서 구성요소들 사이의 영향이 작은 것이 아닙니다.
이런 이유로 CNN이 nlp에 적합하지 않을 수 있지만, 몇가지 모델은 nlp에서 좋은 결과를 이끌어냈습니다. 하지만 자세한 내용들은 저도 공부가 필요하고 이번 튜토리얼 강의 수준을 벗어나기에 링크를 하나 남기고 다른 게시글에서 업데이트 하도록 하겠습니다.
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
RNN (Recurrent Neural Networks)
기본적인 아이디어는 순차적인 정보를 처리한다는 것에 있습니다. 문장에서 다음에 나올 단어를 추측하고 싶다면 이전에 나온 단어들을 아는 것이 큰 도움이 될 것입니다.
각 층들에서 이전 정보를 현재 정보에 연결하여 출력 결과가 이전 계산 결과에 영향을 받게 만듭니다.
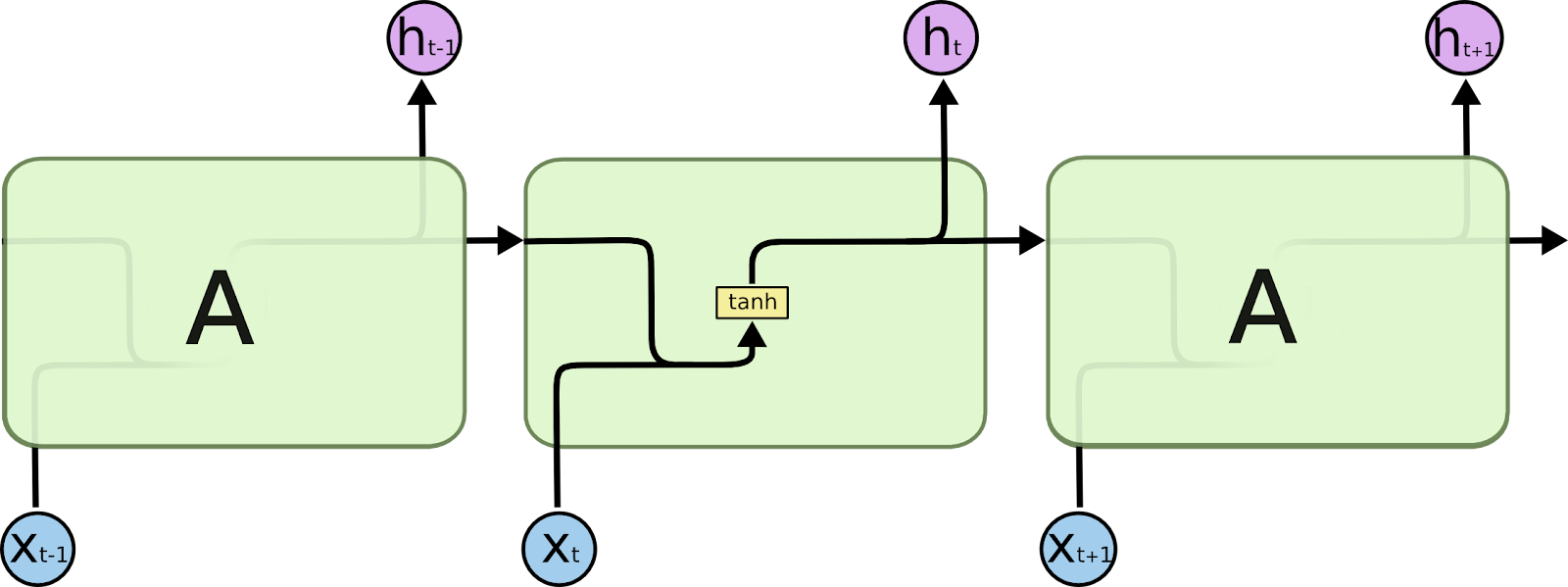
LSTM(Long Short-Term Memory)
RNN에 기존 아이디어는 비교적 짧은 시퀀스만 효과적으로 처리할 수 있었습니다. 이에비해 장기 의존성을 학습시켜 긴 시퀀스를 기억하는데 효과적입니다.

이 또한 더 자세한 설명은 아래의 블로그를 참고하면 좋겠습니다.
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
RL(Reinforced Learning)
경기대학교 최성필 교수님은 Markov Decision Process(MDP)로부터 시작하여 강화학습을 강의했습니다.
MDP에 대한 설명은 아래의 링크를 참조하시기 바랍니다.
https://norman3.github.io/rl/docs/chapter04
MDP에서는 여러가지 용어들이 나오는데 그 개념을 정리하도록 하겠습니다.
에이전트가 관측도구를 통해서 인지하고 있는 자신의 현 상황을 State(상태)라고 합니다. 상태는 에이전트의 Action(행위)에 따라 변합니다. 변화는 상태에 따라 특정 상태의 가치(보상)가 존재하며, 특정 시점 t에서 출발하여 받을 수 있는 모든 보상의 합은 Return(Gt)이라고 합니다. 이 때 먼 미래의 보상은 감가하여 계산하는데 이를 감가적 보상이라고 합니다. 상태 s에서 출발하여 얻을 수 있는 Gt의 기대값을 가치 함수라고 합니다. Policy(정책)은 에이전트의 행위를 결정합니다. 정책은 특정 상태에서 실행 가능한 모든 행위에 대한 확률 분포입니다. 이 때 가치함수는 특정 상태 s의 따라 기대값을 얻는 상태 가치 함수와 행동에 따라 달라지는 보상 정보를 얻는 행동 가치 함수로 나눌 수 있습니다.
강화 학습의 목적은 누적 미래 보상이 최대인 policy를 찾는 것입니다.
강화학습(Reinforcement Learning)은 보상(reward)을 얻기 전에 행동(action)을 수행하도록 에이전트(agent)를 학습시키는 기법입니다.
이번 튜토리얼을 통해 자연어 처리에 A to Z에 대한 개략적인 내용들을 배워봤습니다.
형태소 분석, 문장/구문 분석 방법, CNN, RNN, RL 등을 이용한 분석법 등을 통해 여러분은 chatbot을 만들 수 있고 특정 분야의 예약시스템을 만들 수도 있습니다. 물론 저도 아직 만들어본 적은 없어요. 또 text generation할 수 있고 QA시스템을 만들거나 Machine translation을 만들 수도 있습니다. 이 외에도 다양한 분야에서 활용할 수 있는 방법들의 기본 개념들을 익히셨다고 보면됩니다. 이젠 깊게 파고 들어가야겠죠?
이번 포스팅에서 기본적으로 자연어를 처리하는 방법에대해 간단하게 알아보았습니다.
2018 자연어 처리 튜토리얼의 목적 자체가 이런 느낌 아니었을까요?
2018 자연어 처리 튜토리얼의 등록비용은 15만원 이었습니다. 멋진 강의와 알찬 내용을 준비하신 교수님들에게 박수를 보냅니다.
다만 진행위원분들에게는 쓴소리를 해야할 것 같습니다. 강의장은 추웠고 점심은 맛없었으며 와이파이는 안될 때가 더 많았고 실습강의임에도 멀티탭은 찾기 어려웠습니다. 적은 돈내고 듣는 강의가 아니기때문에 혹시 이 포스팅을 본다면 다음번에는 참고하여 준비해주길 바랍니다.